
PROJECT TITLE
Seira AI - E-Discovery Platform
My Role
I led the end-to-end design, development, and deployment of the Seira AI e-discovery platform.
My responsibilities included product design, full-stack engineering, and cloud architecture across both the Next.js client and Express.js backend. I implemented the intelligent document processing pipeline with Apache Tika and AWS Textract, built the AI-powered semantic search system using AWS Bedrock (Claude 3) and Pinecone, and designed the case management workflow.
I also architected the security layer including MFA (TOTP-based 2FA), role-based access control, audit logging, and PII detection. Additionally, I built case-specific AI chatbots with embeddable widgets, real-time streaming responses, and comprehensive document viewer integrations.
What is Seira AI
Seira AI is an enterprise-grade AI-powered e-discovery platform built for legal professionals to revolutionize document management and discovery.
The platform features intelligent document routing that automatically processes files through Apache Tika or AWS Textract based on document type, supporting PDFs, Word docs, Excel, PowerPoint, emails (.msg, .eml, .pst), images, and scanned documents.
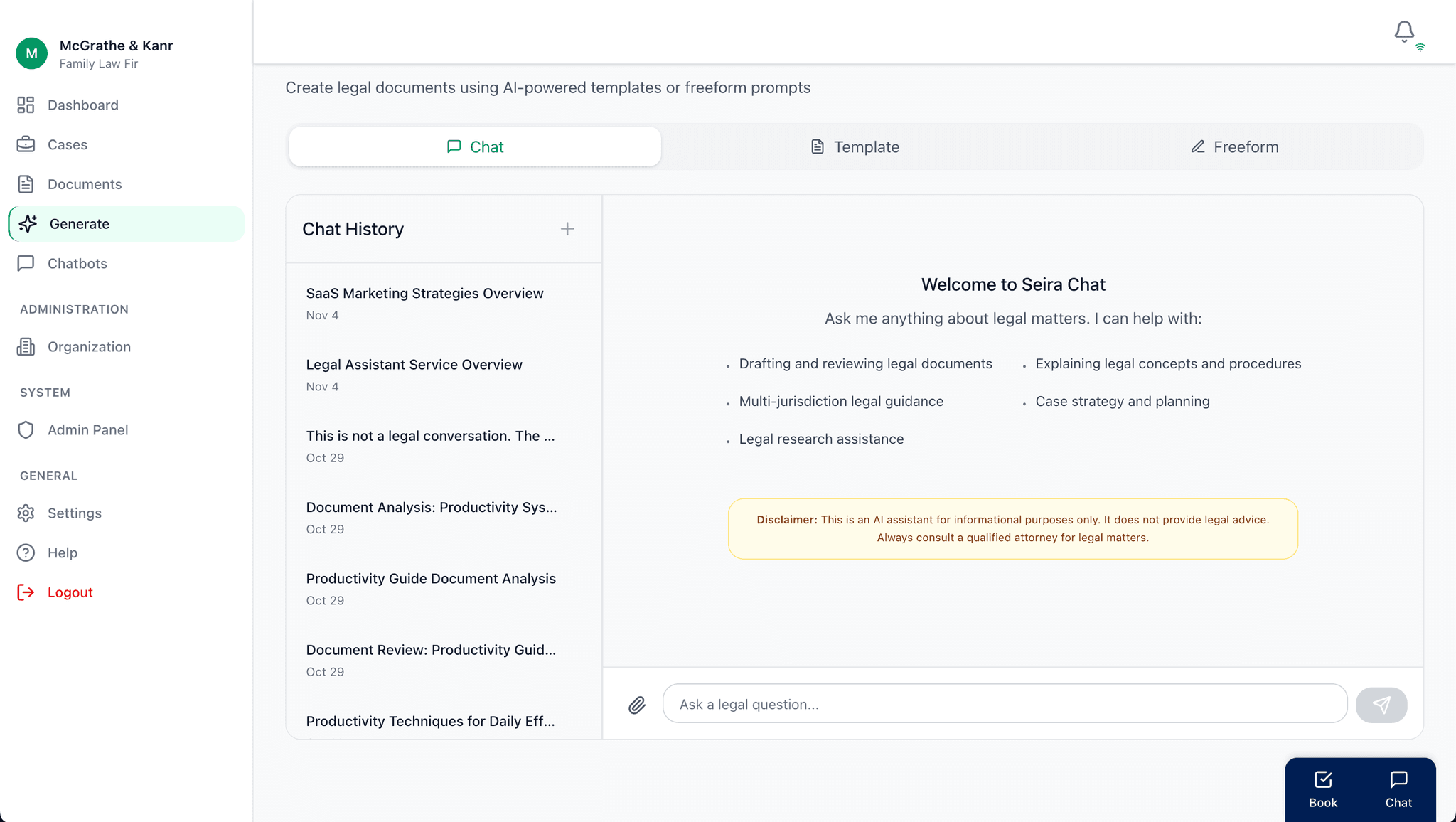
It includes multiple AI-powered search modes (basic, boolean, proximity, semantic, and advanced), case-specific AI chatbots, real-time streaming responses via SSE, and comprehensive audit logging — delivering a complete, secure legal technology solution optimized for Massachusetts family law proceedings.
1. The Problem
Legal professionals handling complex litigation are overwhelmed by thousands of documents per case, making manual review time-consuming, error-prone, and costly. <br/><br/> Traditional keyword searches miss relevant documents, compliance risks increase with manual processing, and there is no context-aware intelligence across massive document sets.
a. User Challenges: Legal professionals struggle with manually reviewing thousands of documents per case, missing critical evidence due to basic keyword searches, and managing compliance risk across multiple document formats including scanned images and emails.
b. Business Challenges: The need for an enterprise-ready platform that delivers AI-powered semantic search, intelligent document classification, PII detection, and audit-compliant workflows while maintaining strict security standards with MFA, RBAC, and encrypted data handling.


Litigation Attorney Persona
Sarah, a family law attorney handling high-asset divorce cases, needs to quickly search through thousands of financial documents, emails, and scanned records to find evidence relevant to asset division and custody arrangements.

Legal Paralegal Persona
David, a paralegal at a mid-size firm, manages document intake for multiple cases simultaneously and needs an intelligent system that automatically classifies, extracts entities, and flags PII across diverse document formats.

Frontend
Built with Next.js 15 and Tailwind CSS 4, featuring Radix UI components, Framer Motion animations, and integrated document viewers for PDFs, images, and Office files.
Backend
Express.js with TypeScript, handling API routes, document processing pipelines, authentication, and real-time streaming via Server-Sent Events.
Database
PostgreSQL via Supabase with Prisma ORM for case management, document metadata, user accounts, audit logs, and processing job tracking.
AI Integration
AWS Bedrock (Claude 3) for semantic search and AI chatbots, with Pinecone vector database for high-performance document retrieval and OpenSearch for full-text indexing.
Document Processing
Apache Tika for text-based extraction and AWS Textract for OCR on scanned documents, forms, and handwritten content — with intelligent routing between the two.
Security
Multi-factor authentication (TOTP), role-based access control, PII detection and flagging, comprehensive audit logging, and data encryption at rest and in transit.
Infrastructure
AWS S3 for document storage with presigned URLs, Redis/Valkey for caching, AWS Lambda for PDF exports, and Docker containers for Apache Tika.
a. Intelligent Document Processing Pipeline
- Built a 3-stage processing pipeline (Analysis → Extraction → NLP) with intelligent routing between Apache Tika and AWS Textract based on document type.
- Implemented real-time progress tracking with status updates for each processing stage.
b. AI-Powered Semantic Search
- Integrated AWS Bedrock (Claude 3) with Pinecone vector database for context-aware document retrieval across multiple search modes (boolean, proximity, semantic).
- Built smart fallback logic and iterative search with document snippet extraction and relevance scoring.
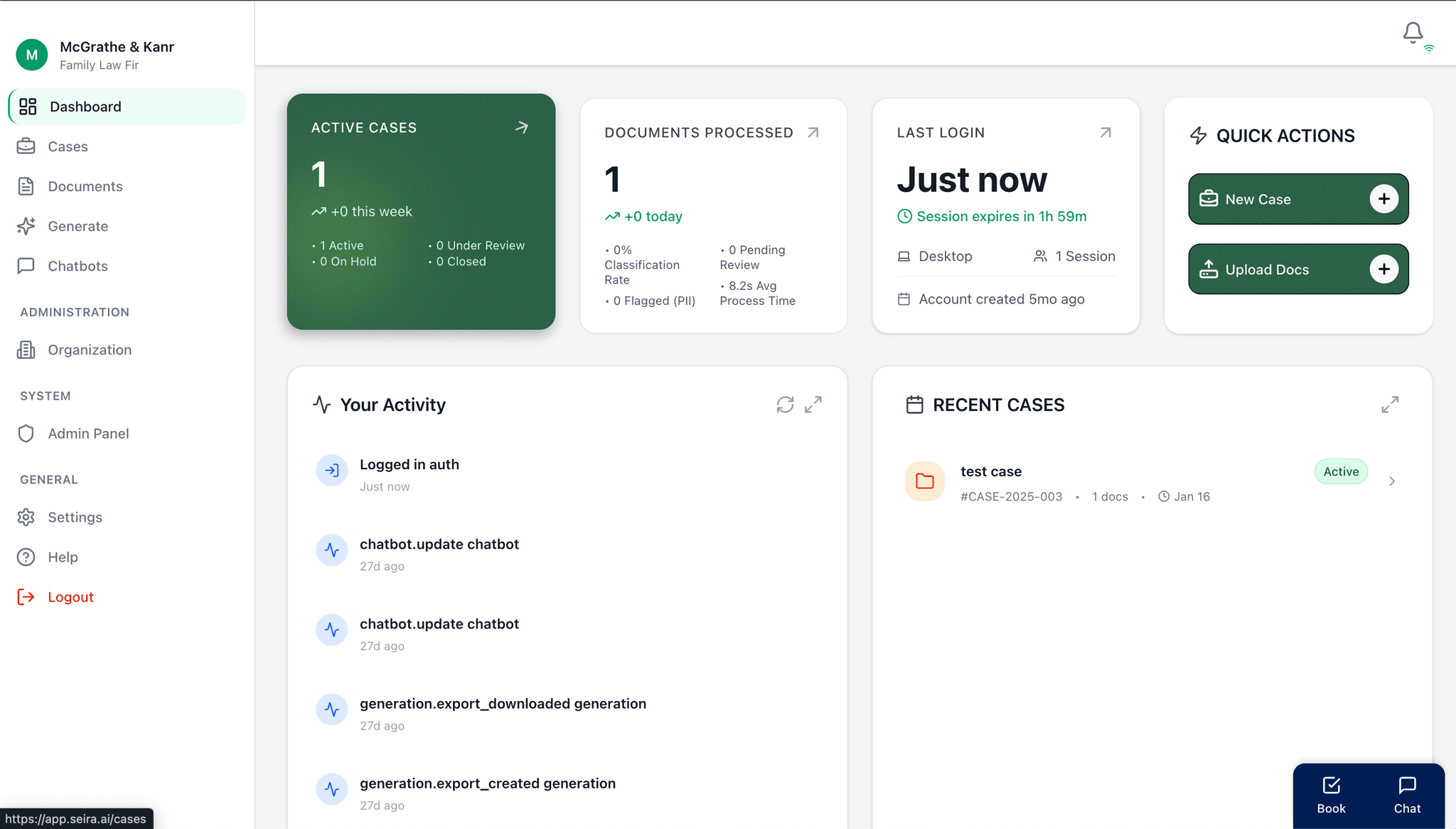
c. Case Management & AI Chatbots
- Designed case-based document organization with status tracking, priority management, and user assignment.
- Built case-specific AI chatbots with embeddable widgets, streaming responses, and configurable behavior.
d. Enterprise Security Layer
- Implemented TOTP-based MFA with QR code setup and backup codes, role-based access control with granular permissions, and comprehensive audit logging.
- Built automatic PII detection and flagging, content sanitization with DOMPurify, and secure document access via S3 presigned URLs.
- Implemented intelligent document routing to minimize processing time — text-based files go through Apache Tika while scanned documents route to AWS Textract.
- Used Redis/Valkey caching for conversation context and search results, reducing repeat query latency.
- Built real-time streaming via SSE for AI search responses and chatbot interactions.
- Designed batch processing with queue-based architecture for handling large document uploads without blocking the UI.
